이 글은 Conditional Image Generation with PixelCNN DecodersAn Architecture Combining Convolutional Neural Network (CNN) and Support Vector Machine (SVM) for Image Classification 논문을 참고하여 정리하였음을 먼저 밝힙니다. 논문에서 사용한 방법론을 간단하게 설명하고, pytorch 라이브러리를 이용하여 코드를 구현한 후 추가적으로 설명드리겠습니다. 혹시 제가 잘못 알고 있는 점이나 보안할 점이 있다면 댓글 부탁드립니다.
0. Summary
일반적으로 Classification에서 사용하는 CNN 아키텍쳐는 FC(Fully connected layer)이후에 Softmax 함수를 이용하여 각 클래스에 속할 확률을 계산합니다. 그러나 이 페이퍼는 Softmax함수 대신에 SVM(suport vector machine)을 사용하는 아이디어를 제시합니다.
1. SVM (L1-SVM, L2-SVM)
수식에서 사용할 linear SVM은 다음과 같은 함수의 마진을 최대화하는 초평면을 찾는 것입니다.
$$f(w, x) = w · x + b, where\;margin = {1 \over ||w||^2}$$
1) L1-SVM
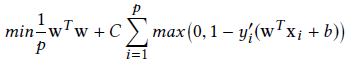
수식에서 최적화하기 원하는 파라미터 w입니다. 여기서 \(w^Tw\)은 Manhattan norm을 말하며, C는 페널티 파라미터 그리고 y prime은 실제 값입니다.
2) L2-SVM
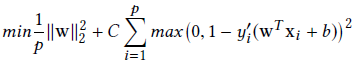
마찬가지로 수식에서 최적화하기 원하는 파라미터는 w입니다. 다만 Manhattan norm 대신 Euclidean norm인 \(||w||_2\)를 사용하고 margin부분에도 제곱을 사용합니다.
2. Model architecture
실험에 사용한 모델의 구조는 다음과 같습니다.

크게 (2)~(4), (5)~(7) Conv, ReLU, Pooling으로 구현된 2개의 큰 블럭을 쌓고, 모델 하부에는 FC와 Dropout을 사용하여 아웃풋 클래스에 맞춥니다. 여기에 (10) layer이후의 softmax함수 대신 L2-SVM을 사용한다.
또한 Optimizer은 Adam을 사용하여 학습합니다.
3. Dataset
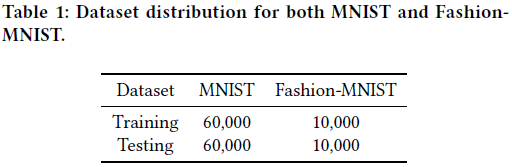
데이터셋은 MNIST와 Fashion-MNIST데이터를 사용합니다.
4. Experiments
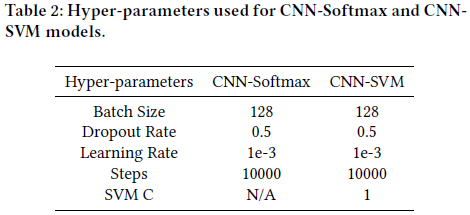
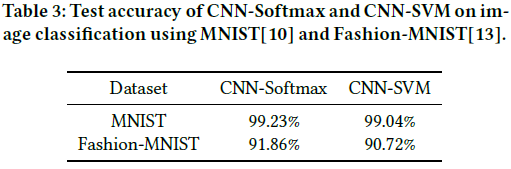
실험의 결과는 아쉽게도 기존의 CNN 아키텍쳐보다 약간 낮은 성능을 보였으나, SVM도 어느정도 softmax 함수 대체로 사용할 수 있다는 결과를 얻었습니다.
5. Code review
학습은 50 epochs만 진행하였습니다.
1) import module
import torch
import torch.nn as nn
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import torch.nn.init
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
2) dataset 설정
'''
필요한 dataset 설정
Mnist & F-Mnist data
'''
class DATASET(Dataset):
def __init__(self, dataname, train, transform=None):
self.dataset = dataname
self.train = train
self.transform = transform
# dataset의 이름에 따라 fashion-mnist, mnist load
if self.dataset == 'Mnist':
self.data = datasets.MNIST('~/.pytorch/MNIST_data/', download=True, train=self.train,transform = self.transform)
elif self.dataset == 'F_Mnist':
self.data = datasets.FashionMNIST('~/.pytorch/F_MNIST_data/', download=True, train=self.train, transform = self.transform)
else :
print(f'We have no dataset {self.dataset}')
assert False
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index]
class data_transform :
def __init__(self, mode):
self.mode = mode
def set_transform(self):
if self.mode == 'train_mode' :
train_transform = transforms.Compose([
transforms.ToTensor()])
# transforms.RandomRotation(90), 실험과 동일한 환경을 위해 agumenation은 사용 안함
# transforms.RandomHorizontalFlip(),
# transforms.RandomVerticalFlip(),
return train_transform
elif self.mode == 'test_mode' :
test_transform = transforms.Compose([
transforms.ToTensor()])
return test_transform
else :
print(f'We have no transform {self.mode}')
assert False
3) model 설정
'''
model 설정
2-layers-CNN model
'''
class CNN(torch.nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.drop_prob = 0.5 # 논문에서 사용한 dropout hyperparameter : 0.5
self.layer1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 32, kernel_size=5, stride=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=1))
self.layer2 = torch.nn.Sequential(
torch.nn.Conv2d(32, 64, kernel_size=5, stride=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=1))
# FC layer
self.FC = torch.nn.Linear(18 * 18 * 64, 1024, bias=True)
torch.nn.init.xavier_uniform_(self.FC.weight)
self.layer3 = torch.nn.Sequential(
self.FC,
torch.nn.Dropout(p= self.drop_prob),
torch.nn.Linear(1024, 10, bias=True))
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1) # flatten
out = self.layer3(out)
return out
4) 학습 환경 설정
'''
학습 환경 설정 :
기존 CNN Loss - CrossEntropyLoss
SVM Loss 설정 - L2 SVM으로 L2-hindge loss를 사용
'''
# GPU 설정
device = 'cuda' if torch.cuda.is_available() else 'cpu'
if device == 'cuda':
torch.cuda.manual_seed_all(1234) # 학습 시드 고정
# 논문에 사용된 학습 파라미터
batch_size = 128
learning_rate = 0.001
training_epochs = 50
def set_model(model = 'CNN', device = device) :
if model == 'CNN' :
model = CNN().to(device)
loss_function = torch.nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
elif model == 'CNN_SVM' :
model = CNN().to(device)
loss_function = torch.nn.MultiMarginLoss(p = 2, margin = 1).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
else :
print(f'We have no model {model}')
assert False
return model, loss_function, optimizer
# dataset 설정
Mnist_train = DATASET(dataname = 'Mnist', train='train_mode', transform=data_transform(mode='train_mode').set_transform())
Mnist_test = DATASET(dataname = 'Mnist', train='test_mode', transform=data_transform(mode='test_mode').set_transform())
F_Mnist_train = DATASET(dataname = 'F_Mnist', train='train_mode', transform=data_transform(mode='train_mode').set_transform())
F_Mnist_test = DATASET(dataname = 'F_Mnist', train='test_mode', transform=data_transform(mode='test_mode').set_transform())
Mnist_train_loader = DataLoader(Mnist_train, batch_size = batch_size, shuffle = True)
Mnist_test_loader = DataLoader(Mnist_test, batch_size = batch_size, shuffle = True)
F_Mnist_train_loader = DataLoader(F_Mnist_train, batch_size = batch_size, shuffle = True)
F_Mnist_test_loader = DataLoader(F_Mnist_test, batch_size = batch_size, shuffle = True)
5) 모델 학습 및 결과 출력
'''
학습 및 테스트 : Mnist & CNN
'''
model, loss_function, optimizer = set_model(model='CNN')
best_score = 0
for epoch in range(training_epochs):
model.train()
train_loss = 0
train_corrects = 0
train_num = 0
for i, (inputs, labels) in enumerate(Mnist_train_loader):
inputs = inputs.to(device)
labels = labels.long().to(device)
outputs = model(inputs)
pred_labels = torch.argmax(outputs, dim = -1)
optimizer.zero_grad()
# loss 및 accuracy 계산
loss = loss_function(outputs, labels)
train_loss += loss.item()
train_corrects += sum(pred_labels == labels)
train_num += labels.size(0)
loss.backward()
optimizer.step()
del loss, pred_labels, outputs, inputs, labels
# test
model.eval()
with torch.no_grad():
test_loss = 0
test_corrects = 0
test_num = 0
for j, (inputs, labels) in enumerate(Mnist_test_loader):
inputs = inputs.to(device)
labels = labels.long().to(device)
outputs = model(inputs)
pred_labels = torch.argmax(outputs, dim = -1)
loss = loss_function(outputs, labels)
test_loss += loss.item()
test_corrects += sum(pred_labels ==labels)
test_num += labels.size(0)
del loss, pred_labels, outputs, inputs, labels
train_acc = train_corrects.cpu().numpy()/train_num
test_acc = test_corrects.cpu().numpy()/test_num
if best_score < test_acc :
best_score = test_acc
print(f'epoch : {epoch}')
print(f'train_loss : {train_loss}, train_acc : {train_acc}')
print(f'test_loss : {test_loss}, test_acc : {test_acc}')
print(f'best_test_score : {best_score}')'''
학습 및 테스트 : Mnist & CNN_SVM
'''
model, loss_function, optimizer = set_model(model='CNN_SVM')
best_score = 0
for epoch in range(training_epochs):
model.train()
train_loss = 0
train_corrects = 0
train_num = 0
for i, (inputs, labels) in enumerate(Mnist_train_loader):
inputs = inputs.to(device)
labels = labels.long().to(device)
outputs = model(inputs)
pred_labels = torch.argmax(outputs, dim = -1)
optimizer.zero_grad()
# loss 및 accuracy 계산
loss = loss_function(outputs, labels)
train_loss += loss.item()
train_corrects += sum(pred_labels == labels)
train_num += labels.size(0)
loss.backward()
optimizer.step()
del loss, pred_labels, outputs, inputs, labels
# test
model.eval()
with torch.no_grad():
test_loss = 0
test_corrects = 0
test_num = 0
for j, (inputs, labels) in enumerate(Mnist_test_loader):
inputs = inputs.to(device)
labels = labels.long().to(device)
outputs = model(inputs)
pred_labels = torch.argmax(outputs, dim = -1)
loss = loss_function(outputs, labels)
test_loss += loss.item()
test_corrects += sum(pred_labels ==labels)
test_num += labels.size(0)
del loss, pred_labels, outputs, inputs, labels
train_acc = train_corrects.cpu().numpy()/train_num
test_acc = test_corrects.cpu().numpy()/test_num
if best_score < test_acc :
best_score = test_acc
print(f'epoch : {epoch}')
print(f'train_loss : {train_loss}, train_acc : {train_acc}')
print(f'test_loss : {test_loss}, test_acc : {test_acc}')
print(f'best_test_score : {best_score}')'''
학습 및 테스트 : F_Mnist & CNN
'''
model, loss_function, optimizer = set_model(model='CNN')
best_score = 0
for epoch in range(training_epochs):
model.train()
train_loss = 0
train_corrects = 0
train_num = 0
for i, (inputs, labels) in enumerate(F_Mnist_train_loader):
inputs = inputs.to(device)
labels = labels.long().to(device)
outputs = model(inputs)
pred_labels = torch.argmax(outputs, dim = -1)
optimizer.zero_grad()
# loss 및 accuracy 계산
loss = loss_function(outputs, labels)
train_loss += loss.item()
train_corrects += sum(pred_labels == labels)
train_num += labels.size(0)
loss.backward()
optimizer.step()
del loss, pred_labels, outputs, inputs, labels
# test
model.eval()
with torch.no_grad():
test_loss = 0
test_corrects = 0
test_num = 0
for j, (inputs, labels) in enumerate(F_Mnist_test_loader):
inputs = inputs.to(device)
labels = labels.long().to(device)
outputs = model(inputs)
pred_labels = torch.argmax(outputs, dim = -1)
loss = loss_function(outputs, labels)
test_loss += loss.item()
test_corrects += sum(pred_labels ==labels)
test_num += labels.size(0)
del loss, pred_labels, outputs, inputs, labels
train_acc = train_corrects.cpu().numpy()/train_num
test_acc = test_corrects.cpu().numpy()/test_num
if best_score < test_acc :
best_score = test_acc
print(f'epoch : {epoch}')
print(f'train_loss : {train_loss}, train_acc : {train_acc}')
print(f'test_loss : {test_loss}, test_acc : {test_acc}')
print(f'best_test_score : {best_score}')'''
학습 및 테스트 : F_Mnist & CNN_SVM
'''
model, loss_function, optimizer = set_model(model='CNN_SVM')
best_score = 0
for epoch in range(training_epochs):
model.train()
train_loss = 0
train_corrects = 0
train_num = 0
for i, (inputs, labels) in enumerate(F_Mnist_train_loader):
inputs = inputs.to(device)
labels = labels.long().to(device)
outputs = model(inputs)
pred_labels = torch.argmax(outputs, dim = -1)
optimizer.zero_grad()
# loss 및 accuracy 계산
loss = loss_function(outputs, labels)
train_loss += loss.item()
train_corrects += sum(pred_labels == labels)
train_num += labels.size(0)
loss.backward()
optimizer.step()
del loss, pred_labels, outputs, inputs, labels
# test
model.eval()
with torch.no_grad():
test_loss = 0
test_corrects = 0
test_num = 0
for j, (inputs, labels) in enumerate(F_Mnist_test_loader):
inputs = inputs.to(device)
labels = labels.long().to(device)
outputs = model(inputs)
pred_labels = torch.argmax(outputs, dim = -1)
loss = loss_function(outputs, labels)
test_loss += loss.item()
test_corrects += sum(pred_labels ==labels)
test_num += labels.size(0)
del loss, pred_labels, outputs, inputs, labels
train_acc = train_corrects.cpu().numpy()/train_num
test_acc = test_corrects.cpu().numpy()/test_num
if best_score < test_acc :
best_score = test_acc
print(f'epoch : {epoch}')
print(f'train_loss : {train_loss}, train_acc : {train_acc}')
print(f'test_loss : {test_loss}, test_acc : {test_acc}')
print(f'best_test_score : {best_score}')
6) 최종 결과
| Dataset | CNN | CNN-SVM |
| MNIST | 99.9483 | 99.90 |
| Fashion-MNIST | 98.68 | 97.1133 |
MNIST는 논문과 비슷한 성능을 보였으며, Fashion-MNIST는 둘다 논문보다 훨씬 좋은 성능을 보였으나 논문의 실험결과와 마찬가지로 두 경우다 CNN이 CNN-SVM보다 조금 더 좋은 성능을 보였습니다.
'논문리뷰 > Image Classification' 카테고리의 다른 글
| MixMatch: A Holistic Approach to Semi-Supervised Learning [NIPS 2019] (0) | 2020.12.25 |
|---|
