이 글은 Conditional Image Generation with PixelCNN Decoders 논문을 참고하여 정리하였음을 먼저 밝힙니다.
논문에서 사용한 방법론을 간단하게 설명하고, pytorch 라이브러리를 이용하여 코드를 구현한 후 추가적으로 설명드리겠습니다. 혹시 제가 잘못 알고 있는 점이나 보안할 점이 있다면 댓글 부탁드립니다.
0. Summary
Image autoencoder를 Conditional PixelCNN과 Gated Convolutional layer를 사용하여 구현하였으며, PixelCNN의 가장 큰 장점은 computational cost가 상대적으로 매우 낮아서 매우 빠르게 학습할 수 있습니다.
1. Gated pixelCNN
우선 PixelCNN이 무엇인지 말씀드리면, 다음과 같이 한 픽셀씩 예측하는 모델을 생각할 수 있습니다.


확률분포의 관여하는 픽셀은 NxN filter에서(가운데 그림에서는 5x5필터의 예시) 원래의 위치에 해당하는 가운데 부분의 픽셀을 기준으로 위의 부분과, 왼쪽 부분만 해당합니다. 컬러 이미지의 경우에 각 픽셀 별로 R, G, B 채널이 존재하므로 생성 순서는 우선 R채널을 생성하고 R채널을 조건부로 G를 생성하고, 생성된 R, G 채널을 조건부로 B채널을 생성합니다.
따라서 인풋을 이미지로 받아 (NxNx3) softmax를 이용하여 각 픽셀 별 256(0~255) 개의 값이 존재하는 NxNx3x256의 예측 아웃풋이 나오게 됩니다.
여기서 Gated PixelCNN은 다음과 같이 Activation unit을 추가한 형태로 표현할 수 있습니다.

k는 k번째 layer, *은 convolution연산, ⊙은 element wise product를 말합니다.
위의 알고리즘은 기존의 pixelCNN보다 모델 내부에서의 복잡도를 잘 반영해 줄 수 있습니다. 또한 PixelRNN아키텍처를 pixelCNN을 이용하여 잘 합친모양으로 병렬화가 쉬운 구조로 설계되었습니다.
2. Blind spot in the receptive field
PixelCNN에서의 문제점은 그림 1번의 맨 오른쪽에서 볼 수 있듯이 맨 오른쪽 아래는 한번도 convolution을 적용하지 않으므로, 무시되는 경우가 발생할 수 있습니다. 저자는 해당부분을 Blind spot이라고 지칭하며 two convolutional network stacks를 제시합니다.
따라서 PixelCNN에서는 보라색으로 표기된 horizontal stack과 파란색으로 표기된 vertical stack, 두 가지 방법으로 stack을 합니다. horizontal stack은 지금까지 설명했던 마스킹(1번 그림의 가운데 그림)을 적용한 방식이고 vertical stack은 마스킹을 적용하지 않고 모든 row를 조건으로 받아드리는 방식입니다.
3. Conditional pixelCNN
기존의 Gated pixelCNN에 latent vector(잠재벡터) h로 표현된 고수준 이미지 표현을 추가하여 conditional distribution을 조정합니다.

즉, 하나의 bias처럼 conditional distribution의 수식을 변형하였으며, 해당 분포를 고려한 수식은 다음과 같습니다.

V는 마스킹 되지 않은 1x1 convolution이고, h는 one hot encoding된 class vector입니다. 위의 수식의 문제점은 class의 해당하는 부분이 pixel의 계산과 관련이 없다는 것입니다. 즉, one hot encoding된 label의 값이 학습에 관여하지 않습니다.
따라서 저자는 latent vector가 학습에 관여할 수 있도록, 수식을 변경하였습니다. 최종 변경된 수식은 다음과 같습니다.

m이라는 매핑을 통해 h는 spatial하게 표현됩니다. 즉, s := m(h)이며 원본 image의 size와 동일하게 매핑되어 임의의 숫자로 이루어진 feature map이 형성됩니다. 또한, V*s 는 마스킹 되지 않은 1x1 convolution입니다.

최종 수식으로 표현한 그림으로 왼쪽은 vertical stack, 오른쪽은 horizontal stack을 표현합니다. 오른쪽의 추가적으로 residual connection은 수식과 별개로 성능을 향상시키는데 사용되었습니다.
4. PixelCNN autoencoder
conditional pixelCNN은 가장 큰 특징인 multimodal image distribution 덕분에 모델 다양성을 생산할 수 있다는 능력을 가지고 있습니다. 즉, 이미지 디코더에 적용하여 autoencoder처럼 사용할 수 있다는 것입니다. 전통적인 autoencoder는 encoder에서 인풋 이미지 x를 더 낮은 차원인 h로 축소한 후, decoder를 통해서 다시 이미지를 복원합니다. 여기서는 기존 autoencoder의 decoder단을 conditional PixelCNN으로 대체한 후 학습을 진행하였으며, 그로인해 낮을 레벨의 pixel statistics는 PixelCNN이 처리해주고 encoder가 좀 더 높은 레벨의 pixel 정보에 집중할 수 있도록 설계되었습니다.
5. Experiments
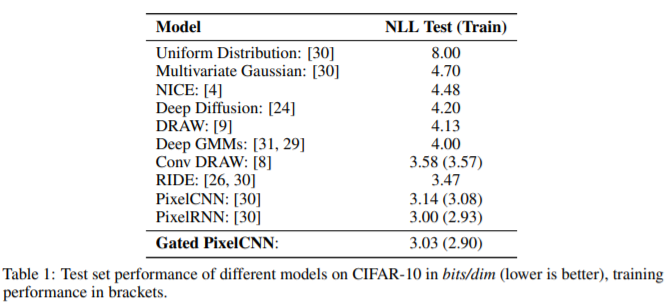
위의 그림은 CIFAR-10 dataset으로 학습하였으며, 각 모델별 최고의 validation score가 나올때까지 학습한 시간의 결과입니다. Gated PixelCNN이 PixelCNN보다 0.11 더 높은 성능이 나왔으며, PixelRNN과 거의 유사한 결과를 얻었습니다.

Table 2는 ImageNet dataset으로 학습한 결과입니다. 이 데이터 셋에서는 모두 Gated pixelCNN이 더 좋은 성능을 보였습니다.
6. code review
1) import module
import time
import numpy as np
import torch
import torch.nn.functional as F
from layers import *
from torch import nn, optim
from torch.utils import data
from torchvision import datasets, transforms, utils
2) Mask type 설정
class MaskedConv2d(nn.Conv2d):
"""
두개의 마스크 타입으로 설정하였다.
A : 첫번째 layer에만 사용하고, mask의 size에 맞추어 그림 1의 가운데 모양처럼 mask를 구현
B : 나머지 layer에 사용하고, 그림 1번에서 가운데 값을 1로 변경
"""
def __init__(self, mask_type, *args, **kwargs):
super(MaskedConv2d, self).__init__(*args, **kwargs)
assert mask_type in ['A', 'B']
self.register_buffer('mask', self.weight.data.clone())
h = self.weight.size()[2]
w = self.weight.size()[3]
self.mask.fill_(1) # 마스크를 모두 1로 채워서
self.mask[:, :, h // 2, w // 2 + (mask_type == 'B'):] = 0 # 마스크가 B타입이면 가운데 값은 0으로 바꾸지 않는다.
self.mask[:, :, h // 2 + 1:] = 0
def forward(self, x):
self.weight.data *= self.mask
return super(MaskedConv2d, self).forward(x)
3) 설정한 각 Mask type을 이용하여 처음 제시했던 Conditional Gate Conv함수를 만듦
class CondGatedMaskedConv2d(nn.Module):
'''
y = tanh(W*x + Vh) ⊙ sigm(W*x + Vh)
'''
def __init__(self, *args, **kwargs):
super(CondGatedMaskedConv2d, self).__init__()
self.masked_conv_1 = MaskedConv2d(*args, **kwargs) # A mask
self.masked_conv_2 = MaskedConv2d(*args, **kwargs) # B mask
self.cond_conv_1 = nn.Conv2d(1, args[2], 1)
self.cond_conv_2 = nn.Conv2d(1, args[2], 1)
self.tanh = nn.Tanh()
self.sigm = nn.Sigmoid()
def forward(self, x, h):
"""
x: 인풋 이미지
h: conditional 인풋
"""
inp = self.tanh(self.masked_conv_1(x))
inp_gate = self.sigm(self.masked_conv_2(x))
cond = self.tanh(self.cond_conv_1(h))
cond_gate = self.sigm(self.cond_conv_2(h))
return inp*inp_gate + cond*cond_gate
4) layer 쌓기
class CondPixelCNN(nn.Module):
"""
앞서 만든 CondGatedMaskedConv2d에 A mask를 씌운 layer를 하나 쌓고, 나머지는 B mask를 씌운 layer를 쌓는다.
추가적으로 학습을 위해 각 layer뒤에 BatchNorm2d을 쌓아주었다.
레이어는 A layer 1개, B layer 6개를 쌓은 총 7 layers 이다. 최종 아웃풋은 256dim이다.
filter의 size는 7, stride는 1, padding은 3으로 설정하였다.
"""
def __init__(self, n_channels=32, n_layers=7):
super(CondPixelCNN, self).__init__()
self.layers = nn.ModuleList()
self.layers.append(CondGatedMaskedConv2d('A', 1, n_channels,
7, 1, 3, bias=False))
self.layers.append(nn.BatchNorm2d(n_channels))
for i in range(1, n_layers+1):
self.layers.append(CondGatedMaskedConv2d('B', n_channels,
n_channels, 7, 1, 3,
bias=False))
self.layers.append(nn.BatchNorm2d(n_channels))
self.layers.append(nn.Conv2d(n_channels, 256, 1))
def forward(self, x, h):
out = x
for layer in self.layers:
if isinstance(layer, CondGatedMaskedConv2d):
out = layer(out, h)
else:
out = layer(out)
return out
5) Label들을 이미지의 크기에 맞춘 one hot encoding으로 변경
def to_one_hot(y, k=10):
'''
label을 우선 one hot encoding시켜줌
'''
y = y.view(-1, 1)
y_one_hot = torch.zeros(y.numel(), k)
y_one_hot.scatter_(1, y, 1)
return y_one_hot.float()
class LabelNet(nn.Module):
"""
One hot encoding된 인풋을 -1~1사이의 값으로 linear하게 변환하여 동일한 size로 리턴함
"""
def __init__(self, input_shape=10, output_shape=(28,28)):
super(LabelNet, self).__init__()
self.input_shape = input_shape
self.output_shape = output_shape
self.linear = nn.Linear(10, np.prod(output_shape))
def forward(self, h):
return self.linear(h).view(-1, 1, *self.output_shape)
6) 학습환경 설정
n_classes = 10
n_epochs = 25
n_layers = 7
n_channels = 16
device = 'cuda'
pixel_cnn = CondPixelCNN(n_channels, n_layers).cuda()
label_net = LabelNet().to(device)
# 로더 설정
trainloader = data.DataLoader(datasets.MNIST('data', train=True,
download=True,
transform=transforms.ToTensor()),
batch_size=128, shuffle=True,
num_workers=0, pin_memory=True)
testloader = data.DataLoader(datasets.MNIST('data', train=False,
download=True,
transform=transforms.ToTensor()),
batch_size=128, shuffle=False,
num_workers=0, pin_memory=True)
# optimizer와 loss함수를 정의하고, 나중에 reconstruction할 sample을 만듦
sample = torch.Tensor(120, 1, 28, 28).to(device)
optimizer = optim.Adam(list(pixel_cnn.parameters())+
list(label_net.parameters()))
criterion = torch.nn.CrossEntropyLoss()
7) 학습 및 결과저장
for epoch in range(n_epochs):
# train
err_tr = []
time_tr = time.time()
pixel_cnn.train()
label_net.train()
for inp, lab in trainloader:
lab = to_one_hot(lab)
lab_emb = label_net(lab.to(device))
inp = inp.to(device)
target = (inp[:,0] * 255).long()
loss = criterion(pixel_cnn(inp, lab_emb), target)
err_tr.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
time_tr = time.time() - time_tr
with torch.no_grad():
err_te = []
time_te = time.time()
pixel_cnn.eval()
label_net.eval()
for inp, lab in testloader:
lab = to_one_hot(lab)
lab_emb = label_net(lab.to(device))
inp = inp.to(device)
target = (inp[:,0] * 255).long()
loss = criterion(pixel_cnn(inp, lab_emb), target)
err_te.append(loss.item())
time_te = time.time() - time_te
# sample을 reconstruct
labels = torch.arange(10).repeat(12,1).flatten()
sample.fill_(0)
for i in range(28):
for j in range(28):
out = pixel_cnn(sample, label_net(to_one_hot(labels).to(device)))
probs = F.softmax(out[:, :, i, j], dim=1)
sample[:, :, i, j] = torch.multinomial(probs, 1).float() / 255.
utils.save_image(sample, 'sample_{:02d}.png'.format(epoch), nrow=10, padding=0)
output_string = 'epoch: {}/{} bpp_tr: {:.7f}' + \
'bpp_te: {:.7f} time_tr: {:.1f}s time_te: {:.1f}s'
print(output_string.format(epoch,
n_epochs,
np.mean(err_tr)/np.log(2),
np.mean(err_te)/np.log(2),
time_tr,
time_te))
8) 결과
차례대로 1epoch, 5epochs, 10epochs학습 후 reconstruction한 결과입니다.



차례대로 15epochs, 20epochs, 25epochs학습 후 reconstruction한 결과입니다.



학습하는데 epoch당 50초 정도밖에 걸리지 않았으며, 25epochs만 학습하더라도 복원이 잘 되는 것을 확인할 수 있습니다.